
This was the capstone research paper I submitted to complete my B.S. in Cybersecurity degree at American Military University. I’ve republished the paper here for purposes of transparency and validation of learned knowledge. I make no claims to expertise based on this research paper alone, but used it as a foundational starting point for implementing enterprise-class email services in the private sector.
Abstract
Email is people-centric. Email attacks target people, not infrastructure. The pervasive threat of email impersonation attacks and their increasing sophistication and prevalence have disrupted legitimate commerce from reliably reaching a user’s inbox. A 2023 report from Fortra observed that 99% of social engineering attacks over email fall into the category of impersonation attempts, with the Microsoft and Google email platforms being prime targets. This paper explores the problem of email deliverability through the lens of enterprise email security and the email authentication process. It begins with a brief history of email to develop a comprehensive understanding of the influences and decentralized nature of the email system. It then discusses email headers, their relevance to email deliverability, their importance to facilitating a democratic communication system, and the drawbacks that allow the system to be exploited. The paper concludes with a detailed examination of email authentication protocols, including DMARC, SPF, DKIM, BIMI, and MTA-STS. Each section is supported by representative data, comprehensive case studies, illustrative vignettes, and mapped tables guiding readers towards thoughtful considerations of potential solutions.
Enterprise Email Security: A Forensic Examination of the Email Authentication Process
Zig Ziglar is often credited for succinctly defining what we intuitively know about human nature but are often challenged to instinctively recognize. “Every sale has five basic obstacles: no need, no money, no hurry, no desire, no trust.” (Kawasaki, 2011). In the digital age, snake-oil salesmen still seem to use this maxim to greater effect than legitimate business. On June 18, 2020, a malicious actor launched an impersonation attack against 20,000 employees of Wells Fargo Bank. The attack itself was relatively simple, employing a reuse to trick targets into parting with sensitive account credentials. However, security researchers suggested the attack was successful largely due to two clever tactics, instilling a sense of urgency and going to great lengths to impersonate genuine Wells Fargo communications and web site (Crosman, 2020).
The efforts of the malicious actors overcame two common objections. No hurry and no trust. Their targets believed they had to act fast to protect their accounts, seeding prudence for the perception of safety, and were encouraged by a sense of trust from familiar surroundings. The message looked right and appeared to come from the right place. The ultimate number of accounts compromised is unknown, but the scale of Microsoft 365 and Wells Fargo’s coordinated response suggests the potential for compromise was severe.
An article titled “Email Impersonation Attacks Reach All-Time High According to Latest Report from Fortra” published by The Database and Network Journal (TDNJ) (2023) provided a comprehensive break-down of the latest statistics on the topic. The authors noted that within the category of social engineering attacks over email, 99% are email impersonation attempts. Impersonation attacks can be particularly deceptive because they attempt to present themselves as originating from a major brand and often utilize the same templated message format as legitimate communications. For example, a password reset request may appear identical in both visual format and coded markup, with the only noticeable difference being a grammatical error or overly aggressive call to action. In fact, a key finding of the TDNJ report noted that approximately 60% of impersonation attacks claim to be from Microsoft or Google. This matches data that suggests Microsoft and Google are the most abused email platforms, with 18.3% of email attacks originating from Microsoft servers and 67.5% coming from Google. It follows that impersonation attacks are more effective when actually originating from the service they claim to be.
While the volume of abuse of Microsoft platforms is significantly lower than Google, it is worth noting that between Q4 FY22 and the time of the TDNJ study in Q3 FY23, Office 365 phishing attacks doubled in volume. Some rough math based on validated, peer-reviewed data paints an astonishing picture of the problem. Of the 295.2 Billion spam email messages sent daily (Demand Sage, 2023), 36% are global advertising messages while the remaining 64% are categorized as malicious, though not necessarily carrying malware. This implies that somewhere between 17 Billion and 34 Billion malicious email messages, the overwhelming majority of which are impersonation attacks, originate from the Microsoft 365 platform every 24 hours. And, as previously noted, this only accounts for the 18% of spam that relies on Microsoft’s platform. Google’s email platform sends more than three times that amount. Breaking these numbers down further into hourly send rates is wholly unnecessary, as the daily numbers soberingly demonstrate the competition legitimate messages face when it comes to inbox deliverability (“Email Impersonation Attacks Reach All-Time High According to Latest Report from Fortra,” 2023).
Global business is looking to cybersecurity experts to provide answers. How did we get to this point? Why is email so complicated? How do we protect our brand identity while also communicating effectively with our clients? During the course of this study, one business leader even stated the issue matter-of-factly. “Tell me what I need to pay for my email to be delivered.” he said, requesting to remain anonymous to avoid negative industry attention. “Every message missed by a client could cost us thousands in lost revenue.”
A Brief History of Email
Electronic mail existed before computer networks did. With the introduction of time-sharing systems in the 1960’s, users were able to leave messages for other users on the same system. The messages were not actually “sent” anywhere, but rather saved in a shared user space. This mode of communication was designed to facilitate academic discussion and collaboration, largely around computer science topics. The metaphor of “mail” was a matter of convenience. Users could check for new messages at their convenience and prepare a reply whenever they were ready. The free structure and informality encouraged a “stream-of-consciousness” type of discussion. There was no need provide a full, written academic proof or even stick to a single topic. One could discuss the latest sports scores in the same message about optimizing compile times.
The foundations of what we know as email today came together in 1971 when Raymond Tomlinson insightfully combined the idea of locally-stored mail with the peer-to-peer file-transfer capability of the US Advanced Research Projects Agency (ARPA) computer network, ARPANet. However, the idea of sending an electronic message across a computer network was far from novel. In fact, it was an intuitive, if not obvious, use of the technology invariably hypothesized in the mental simulations of many scholars and researchers, not the least of which included Dick Watson, Abhay Bhushan, Bob Clements, Nancy Neigus, and John Vittal. Still, it took several more years and many contributors worldwide before the system for sending and receiving electronic messages was fully formed and adopted as a standard. Crediting Raymond Tomlinson as the “inventor” of email is more of a recognition of the importance of the @ symbol as a standard in email communication, which Tomlinson chose as the separator between the username and the hostname in his original design. It was not until 1975 that the @ symbol emerged as an addressing standard (Partridge, 2008, pp. 2, 4–5, 7).
Partridge (2008) observed that “much of how email has evolved has depended on seemingly obscure decisions” (p. 3) that shaped the complexity of the system while retaining its nature as the penultimate, open, unfiltered, decentralized, democratic communication system that we have today. The earliest versions of email relied on file copy procedures that were modified to work over the network. This spurred the development of the first version of the File Transfer Protocol (FTP). The community of email users wanted a generalized file manager that operated across a network much the same way their local file manager worked. A single tool to create, copy, move, rename, and delete files on remote machines that runs as a service, agent, or daemon. Every client a server, and every server a client.
The first informal email summit took place in April 1972, where interested parties from various organizations gathered at the Massachusetts Institute of Technology to discuss emerging ideas and further formulate a set of standards. Discussions focused on revisions to FTP and the use of text commands rather than binary to improve the interactive nature of the protocol. A major decision that is still in effect today is the use of American Standard Code for Information Interchange (ASCII) format character mapping. All of the modern subsystem commands that move email across the Internet are simple plain-text commands, and the End-of-File marker remains to a lone period on a single line (Partridge, 2008, pp. 4–5).
Another major change to FTP made later that same year was the symbolic linking of the receiving machine’s memory buffer to the addressed user’s mail file on their local host. The first version of FTP attempted to write directly to the local user’s mail file by appending the incoming text to the file. This approach worked fine internally where networked computers all tended to use the same operating system and network protocols, but messages sent inter-network were prone to failure as the naming convention of the user mail file varied. If a “file not found” error was returned, the message failed to deliver. With a symbolic link, however, the text could be received by any FTP compliant client which would then translate the message into the local mail file format, thereby overcoming system-specific limitations (Partridge, 2008, p. 5).
With the decoupling of the message transfer agent from client-side message handling, the natural next step was to create independent user interfaces–email clients. A key challenge faced by early email clients was the lack of a standard header for email messages. While ASCII had been agreed upon as the file format, and “username@hostname” was the agreed standard for addressing, the memo-style layout we know today (To:, From:, Subject:, Message:) had yet to emerge. This meant that messages were easily delivered, but not so easily read. Unfortunately, dissent amongst the early collaborators also meant the problem was not so easily solved. Despite its popularity, no measurable progress would be made on email for a further three years (Partridge, 2008, p. 7).
By mid-1976, John Vittal had developed a deceptively simple user-agent called MSG that was based on the email client Bananard. Because there was no agreed upon standard, email clients had to create their own user-agent methods to handle messages. This complicated things like delimiters and parsing of message headers. The solution was again to decouple the user-agent handling from the email client, which finally allowed a unified, end-to-end email system to emerge. MSG was, of course, not the only user-agent in development, but it may have had an outsized influence as Vittal was involved with the official Hermes user-agent project at BBN and the Mail Handler (MH) project at RAND Corporation while working on MSG as a side project on nights and weekends (Partridge, 2008, p. 8).
Finally closing the message header issue in 1982 was another major step forward. Partridge (2008) observed that “developing a message [header] format was a difficult intellectual problem…semantically comparable in complexity to the computer language specifications of the time.” This was largely due to the various message transfer agents being developed in a vacuum. “Each operating system would implement an MTA, which was then refined over the years to deal with environmental conditions.” (p. 11). However, now the developers were presented the challenge of preparing email for use on the Internet.
On an Internet based email system, messages would need to be routed rather than peer-to-peer. This means each message transfer agent would need to know both who the message was for and where the message was to be delivered. Because existing message transfer agents connected directly to the remote machine it was addressed to, it only needed to pass the username part when sending a message. In a routed system, however, a message would need to pass through multiple transfer agents, dubbed email gateways, on its way to the delivery destination. This meant that messages would need to be “wrapped in an envelope” and “stamped” with the From username, the originating gateway, the To username, and the delivery destination. In addition, every gateway in between would need to stamp the message so that the delivery route could be tracked in the message header just in case the message could not be delivered at the destination (Partridge, 2008, p. 17).
In many ways the email system is still in development today. Protocols have improved and, in many cases, have been entirely replaced by new standards. Email is still text-based but is largely ANSI instead of ASCII to support international languages and characters in addresses. Multimedia can be encoded into plain text with the Multipurpose Internet Mail Extensions (MIME) standard. Messages can be signed, encrypted, verified with a delivery receipt, and validated against lists or authorized senders. And yet, real email security remains elusive.
The Danger in the Design
The speed, convenience, simplicity, and ubiquity of email makes it an ideal platform for sharing information that drives business. However, those same features also make email a primary platform for incidental data leaks in the performance of everyday tasks (Kaur, Gupta, & Singh, 2018). The routine nature of sending and receiving email quickly develops into an attitude or culture of complacency in the exchange of information. Complacency leads to inherent trust, which culminates in overlooking sometimes even the most obvious indicators of foul play. Malicious actors take advantage of this inattentiveness to trick undiscerning users into parting with sensitive information.
The Problem of Unsecured Email
Security was never really a consideration during the development of email. The earliest systems were peer-to-peer, so messages were delivered directly to the destination with no hosts in between. When email was adapted to the Internet, the focus was on universal interoperability, not really security. This is evident in the development of the email gateway system that was used as open-relays to route email across the Internet and translate arriving messages into the appropriate network architecture (Partridge, 2008). There generally was no login requirement or sender validation. A server identifying itself as a Simple Mail Transfer Protocol (SMTP) relay would be inherently trusted as long as it spoke the common language.
Spammers quickly took advantage of email’s open design to fill every Internet subscriber’s inbox with unwanted messages. Even the kind of spam that is sometimes unintended, as Gary Thuerk, the first person to ever spam a network, can attest. One early technique of sending spam was to connect directly to a server of a recipient organization and submit a message for delivery to every known subscriber. This avoided the need for each message to be routed and mitigated the risk of exceeding timing or bandwidth thresholds. And because messages did not need to be routed, they did not need to come from a valid sender (Baran, 2013, pp. 2260–2261). The sender and gateway information in the email header could be entirely falsified, and yet delivery rates could easily reach 99%. Connect to enough recipient organizations from a long list of open relays and you could covertly deliver your message to tens of thousands of addressees with no way for them to respond or unsubscribe.
Exploitation of the email system has not been limited to just questionable marketing practices but has also been taken advantage of by thieves hawking stolen goods, drug dealers pushing illegal products, scammers taking advantage of the vulnerable, and hackers spreading malware for the “lolz” or with true malice. States attempting to quell the problem by imposing legal consequences failed to address the covert nature of the practice. The creatively named “Controlling the Assault of Non-Solicited Pornography and Marketing (CAN-SPAM)” Act of 2003 established requirements for affirmative consent before a business could send marketing messages to a consumer. However, an annual analysis of spam traffic published by Symantec revealed the exponential growth of spam as a mass marketing method. Spam constituted just 8% of total Internet email traffic globally in 2001. By 2005 that number reached 70%, in 2011 it was 77.8%, and by 2023, 85.8% of all global email traffic was categorized as spam (Baran, 2013; Demand Sage, 2023).
The Problem of Impersonation
Email impersonation is a malicious tactic where the attacker pretends to be a trusted identity. TDNJ (2023) noted that “email impersonation threats are proving to be the most difficult to block as social engineering helps cybercriminals successfully deceive both end users and the security tools designed to protect them” (p. 24). Email impersonation attacks can be categorized into three levels of sophistication. Level 1 includes rudimentary tactics that mimic official communications. Level 2 includes complex tactics that appear to originate from a legitimate domain but are actually fraudulent. Level 3 includes advanced tactics that either appear to originate, or validly do originate from a legitimate domain.
Rudimentary tactics typically employ email templates that are copied from an official communication from the organization they are attempting to impersonate or may simply use a similar color scheme and logos scraped the organization’s website. They often also include official-sounding email addresses but combine them with a generic email provider, such as att_support@gmail.com. These rudimentary tactics are popular because they require little skill or effort from the scammer but are easily defeated by automated systems and attentive users. However, if a scammer can get an inattentive user to click a nefarious link and submit their login credentials, the stolen account can then be used for more advanced attacks (Craig, 2022).
Complex impersonation attacks require the attacker to make more active attempts to defraud the user. One such method is “typosquatting”, where the attacker will register a common miss-spelling of a word in a domain, such as amzon.com or linkdin.com. This can capture users that make the typo mistake without noticing and trick users that do not pay close attention. Another complex method involves the use of a similar-looking domain to the organization they want to impersonate, such as g00gle.com or microscft.com. However, browsers and popular Domain Name System (DNS) servers easily protect against this type of attack, and few users would be tricked by a simple character swap (Craig, 2022; Umawing, 2017).
Also within Level 2 impersonation, there is the advanced “homographic” attack that can trick even the savviest Internet users. Like email headers, the initial DNS standard only allowed the use of ASCII characters in registered domain names. This decision simplified the design of DNS but entirely excluded world languages that are not based on Latin-script characters. Serious discussion around Internationalized Domain Names (IDN) began around 1996, and various Internet Engineering Task Force Request for Comments (RFC) proposals were adopted over the next 20 years that slowly introduced Unicode text (“ICANN Bringing the Languages of the World to the Global Internet”, 2016). “Stringprep protocols” in RFC 3454 were intended to prevent certain Unicode characters in IDN with Latin-like glyph characteristics from being mapped to DNS (Hoffman & Blanchet, 2002, p. 4), but errors and variance in implementation allowed top-level domain names with technically different characters, but striking similarity to major trademarks, to be registered (Umawing, 2017).
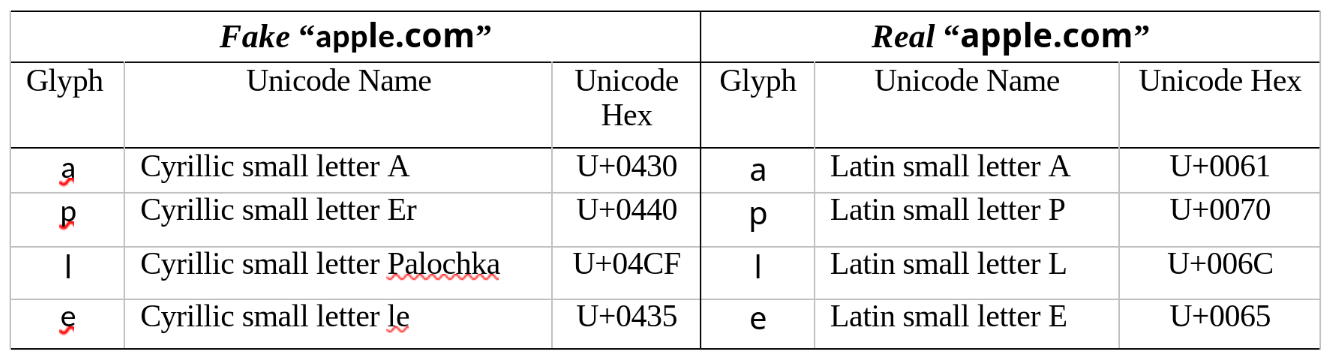
In the “typosquatting” example provided above, the domain g00gle.com clearly used a “0” (digit zero) character instead of an “o” (small letter o) character. In Unicode, the digit zero character is encoded as U+0030, while the Latin small letter o is encoded as U+006F. This is why, under the hood, the domains g00gle.com and google.com are mathematically distinct. A cunning attacker may try to register the domain google.com with the Latin small letter o (U+006F) for the Greek small letter Omicron (U+03BF). But, again, if you look under the hood, you end up with two mathematically distinct domains that look almost identical on the surface (Umawing, 2017). Table 1 provides a comparative example using the domain “apple.com” with contrasting Latin and Cyrillic characters.
Table 1
Cyrillic versus Latin glyphs.
Note. The Glyph column uses the Microsoft Segoe UI Symbol typeface for demonstration purposes. From “Out of character: Homograph attacks explained” by J. Umawing, 2017, Malwarebytes Labs (https://www.malwarebytes.com/blog/news/2017/10/out-of-character-homograph-attacks-explained/). Copyright 2017 by Jovi Umawing.
Case Study 1
In 2015, security researcher Paul Moore demonstrated the danger of the homographic attack by registering a domain for Lloyds Bank, a major international bank based in the United Kingdom, and successfully obtaining a Secure Socket Layer (SSL) certificate that allowed web browsers to show visitors the connection was secure. Moore’s intent was not malicious, but rather to show how easy it is for someone to establish a web presence, completely in the open, impersonating a legitimate company, and with no attempt to be duplicitous. The domain registrar and certificate authority, Cloudflare, sold the domain to Moore in accordance with the Internet Corporation for Assigned Names and Numbers (ICANN) standard procedure. There were no additional security checks simply because the domain name contained the word “bank” in it. In addition, there were no checks against trademark ownership and the domain ownership validation process was insufficient (Cluley, 2015).
The validation process for issuing an SSL certificate, in this case the base-level Domain Validation tier, simply requires proof of domain ownership and an acceptable form of payment. There are no checks to verify who owns the domain, just that the person requesting the SSL certificate has control of the domain’s DNS entries. Control of DNS implies ownership of the domain. Clearly, in cases of a DNS Cache Poisoning attack or a registrar simply being hacked, the Domain Validation tier does not provide sufficient validation of ownership. Checking domain registration requests against a trademark list is not customarily part of the registration process, although some registrars offer it as an additional service. As in the case with Moore’s demonstration, it is the responsibility of the registering party to verify trademark infringement (Shewale, 2023). To Cloudflare’s credit, the SSL certificate was revoked and the fraudulent domain was flagged as a possible phishing attempt within about 48 hours of the domain being registered (Cluley, 2015).
To a certain extent, people are expected to behave altruistically on the Internet. You could say that it is part of living in a modern society. Unfortunately, malicious actors demonstrate little regard for pluralism and do not feel that they are beholden to the accepted social rules. The knee-jerk reaction to this type of incident is to increase regulation of the domain validation process. For example, by requiring a higher level of validation for domain registration and proof of ownership. However, there has to be a checks-and-balances structure to these types of cybersecurity matters. How much of the trademark validation process is the responsibility of the registrar versus the responsibility of the trademark owners? And, if the responsibility lies at the registrar level, why not extend that responsibility down to the browser developers or Internet service providers to hold them accountable for allowing a user to access a website that is full of trademark infringement? These sound like sensational ideas, but they may be seen as reasonable to some cybersecurity professionals on the grounds that it makes the Internet safer. Well, then the argument could be made that stricter rules for registering a basic SSL certificate would lead to fewer services employing SSL protection. Less encryption on the Internet would be bad for all users.
A more reasonable approach would be for users and organizations to take responsibility for their own security. Some ways to prevent such attacks include block-listing newly registered domains, domains that use non-Latin characters or characters that are outside of your operating region’s native language script, and domains that use specific, confusable Unicode characters like the Cyrillic small letter A. These types of protections are often included in modern, mainstream web browsers like Mozilla Firefox, Google Chrome, Microsoft Edge, and Apple Safari, but may not be included natively in development browsers like Chromium, Webkit, and Epiphany. It is also a good practice for organizations to encourage good “web hygiene” during cybersecurity awareness training. This can include “Think Before You Click!” and “What’s Your Browser?” campaigns. Users should be taught to look for signs of phishing, like spelling errors, poor grammar, colors and layouts that look “off”, and calls for urgent action like resetting your password or buying gift cards for your boss.
Case Study 2
In 2017, the Principal Researcher for the NewSky Security blog, Ankit Anubhav, discovered a homographic attack already active in the wild that targeted users looking to download software from Adobe. The attacker registered the domain adoḅe.com with the Lattin small letter B (“b”) cleverly substituted for a Latin small letter B with dot below (“ḅ”). The domain was also issued an SSL certificate with Domain Validation from Let’s Encrypt to further establish trust with the target and support the reuse of the fraudulent domain. Targets were provided a link with a free download that appeared as:
https://get.adoḅe.com/es/flashplayer/flashplayer26_pp_xa_install.exe
and was designed to fool them into believing they were downloading the legitimate Adobe FlashPlayer. If the target took the time to check the SSL certificate, their browser would show them a green lock with “Verified by: Let’s Encrypt”. The layout of the fraudulent website was also mimicked the colors and graphics of the official Adobe website. The attacker also copied the registrant information of the official Adobe domain. A WHOIS lookup of the registrant information of the fraudulent domain showed the owning organization as “Adobe Systems Incorporated” including the correct city, zip code, and street address. However, the attacker submitted “Mexico” as the state instead of “California”, drawing scrutiny to their operation (Anubhav, 2017).
Once downloaded and executed, the binary install package labeled as Adobe FlashPlayer first checked the target machine for common anti-virus applications, and would not attempt to install the payload if the anti-virus package was active. Otherwise, the install continued and injected a customized variant of the “BeatBot C2” botnet agent. The agent registered the compromised machine as a node in a distributed Bitcoin mining operation. The agent also had the ability to scan the contents of the compromised machine’s hard drive and exfiltrate data to a control server in Russia (Anubhav, 2017).
The extent of the compromise is unknown, and additional details about the attack, including when the fraudulent domain was registered, the registrar, and the SSL certificate issuing authority, was not available as the original contents of the security report were removed from the public PasteBin location where it was posted for public review. The extent of damages to Adobe was also unavailable at the time of research. However, similar attacks have resulted in severe damage to the reputation and brand integrity of other trusted technology companies. In September, 2018, Facebook revealed the details of an attack of its systems that affected as many as 30 million users and required 90 million users to re-validate their accounts. The announcement had an immediate impact on the public valuation of Facebook, resulting in the loss of $36 billion (Isaac, 2018).
A later study by Greg Belding of the Infosec Institute (2018) noted the astonishing damages that can result from a phishing attack. On average, a successful attack will cost the target organization $3.92 million. Associated damages include data loss, identity theft, and eroded trust that can cost an organization significant loss in business for several years after an attack. In general, customers are 42% less likely to continue business with the compromised organization, and the reputational damage may also impact partnerships with vendors. Finally, email inbox placement can fall by as much as 10% among the major email providers (Belding, 2020).
The Email Header
From a cybersecurity perspective, the email header records a forensic record of the pattern of life of an email message in the sense that headers are scientifically observable, reliable, predictable, and repeatable. The authenticity of every message is hidden in the details of the message header. Over time, experts have developed automated systems that can scrutinize headers in real time as a message traverses the Internet and make accurate decisions about authenticity and deliverability. One early version of this idea was Secure MIME (S/MIME). However, modern authentication leverages Domain-based Message Authentication, Reporting, and Conformance (DMARC) with DomainKeys Identified Mail (DKIM) and the Sender Policy Framework (SPF) (Kucherawy & Zwicky, 2015).
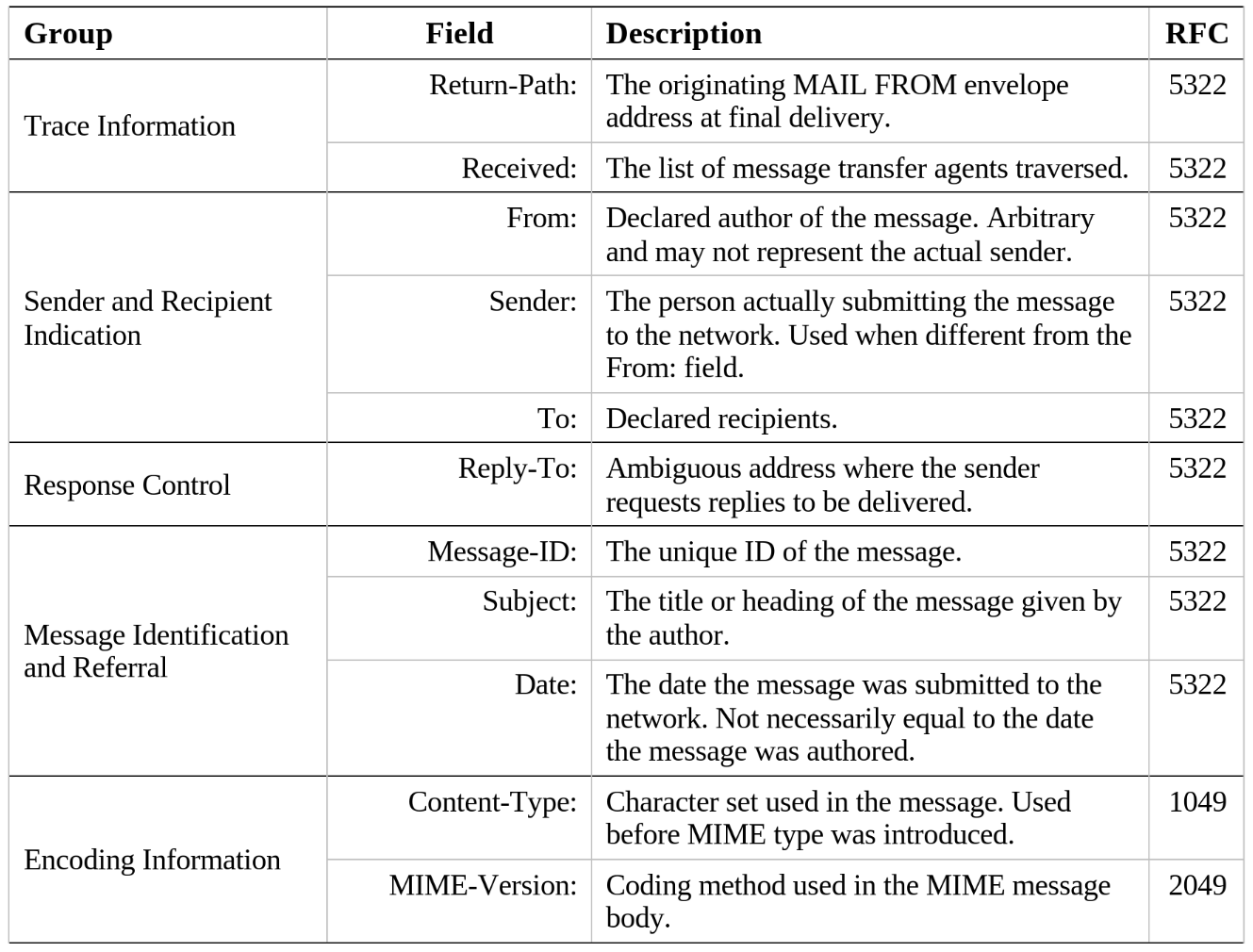
The “header” of an email message contains addressing and other metadata about the contents of the message and its path through the Internet. It is so named because it can be found at the top of a raw email file even though the header is generally not visible to the user by default. The actual content of a header is designed to be variable to enable message transfer agents, user agents, gateways, and service providers to pass tailored information across their platforms, but there is also a Common Internet Message Headers standard defined by several RFC and consolidated into RFC 2076 by Jacob Palme (1997). The complete message header definition is too extensive to include here. For the sake of brevity, this research project focused on the essential headers that are strictly relevant to the email authentication process. Table 2 provides a concise description of the relevant email header fields organized by their standard header group.
Table 2
Note. Adapted from the information contained in RFC 2076, “Common Internet Message Headers” by J. Palme, 1997, Internet Engineering Task Force (https://datatracker.ietf.org/doc/rfc2076). Copyright IETF Trust and the persons identified as the document authors.
Understanding the relevance of each email header field is critical to the analysis process. Anomalies can be easily spotted by comparing expected results to actual results, but only if you can calculate the expected result accurately. For example, an email can claim to be from a trusted sender and appear to be reputable using the techniques presented in the case studies presented earlier. However, a careful analysis of the headers could reveal inconsistencies between the declared originator and path, and the actual originator and path. This may be cause for alert or justification for alternate delivery, such as delivering the message to the spam folder instead of the inbox, depending on the settings of the recipient’s security preferences and email provider requirements.
Trace Information in the header includes the Return-Path: and Received: fields. The Return-Path: is comparable to the return address on a letter sent via the postal service. Generally, the post office and the letter recipient expect the return address to be the same as the sender’s originating address. But when you are addressing a letter, you can arbitrarily write any address you want, including a fake address, and your letter will still likely be delivered. The Received: field is comparable to the post mark stamped on your letter at the originating post office. When your letter is delivered, close examination will reveal that the false return address provided does not match the post mark, which should raise suspicion about the veracity of the letter. Similarly, a Return-Path: with a Gmail address and a Received: field indicating Yahoo! As the originating gateway may be cause for concern (Resnick, 2008).
Sender and Recipient Indication includes the From:, Sender:, and To: fields. The From: field is arbitrary and can be changed like the Return-Path: field. This will be an important detail when discussing DMARC. The Sender: field will contain the address of the sending user-agent when it is different from the From: field (Resnick, 2008). The To: field must contain at least one valid address to be delivered, but placing multiple invalid recipient addresses in the To: field is a known phishing tactic where the attacker attempts to lend credibility to a message by including the names and addresses of individuals known to and trusted by the target. It is the email equivalent of “name dropping” where one person attempts to gain leverage over another by referencing persons of repute, importance, or greater social status.
The Response Control group only includes one header field that is particularly relevant to email authentication. The Reply-To: field follows the trend of being arbitrary and ambiguous. The general expectation is that the Reply-To: field will contain the same address as the From: and Return-Path: fields, but may be altered by the user-agent to be any email address as long as it is in the proper format (Resnick, 2008).
The Message Identification and Referral group includes the Message-ID:, Subject:, and Date: fields. The Message-ID: is generated by the sender and should be globally unique. Every individual instance of a message should have its own unique Message-ID:. For example, if you send an email to one recipient, and then decide to copy and paste the same content and subject into a new email with two recipients, one of whom is the same as the first message, the result will be two instances of the email even though the content is the same. All copies of the second message, which is delivered to two recipients, will have an identical Message-ID:. However, the first message and the second message will each have their own unique Message-ID:. The Subject: field is a message descriptor provided by the sender and is unencrypted by default, even for messages that are explicitly encrypted. The Date: field is stamped by the user-agent at the time the message is submitted and may not correlate to the time a message was actually authored. For example, a message can reside as a draft for an arbitrary period of time before being submitted (Resnick, 2008).
Encoding Information contains the Content-Type: and MIME-Version: fields. The two fields are closely related. Content-Type: is one of the original headers defined in RFC 1049 in early 1988 as an indicator of the character set used in the message (Sirbu, 1988). For example, ASCII versus ANSI. The field is only used in modern email when the message is in an unencrypted plain text format. Typically, a header will contain a MIME-Version: instead of a Content-Type:. Borenstein and Freed (1996) introduced MIME as a redefined message format that supports multiple data types. For example, an email attachment can be declared as a “image/jpeg” so that the email client knows how to handle the attachment. While invariantly useful, MIME is easily exploited by declaring an incorrect format, like attaching a zip archive but declaring it as a PDF. In a surprising number of cases, this simple tactic can be used to infiltrate binaries or exfiltrate data that would otherwise be filtered, provided that the recipient knows the correct format for conversion.
S/MIME
Defined in RFC 8551 as an accepted internet standard, S/MIME implemented a protocol for “adding cryptographic signature and encryption services to MIME data” (Schaad et al., 2019, p. 5). The design was intended to provide four key functions: authentication, message integrity, non-repudiation of origin, and data confidentiality. All four functions are effectively provided by the implementation of public key cryptography, which uses a two-part, asymmetric encryption algorithm to encrypt data with the need to exchange a shared secret. The system works by generating a private key that the user holds as their secret, and a corresponding public key that they can distribute. When someone wants to send the user a secure message, they use the public key to encrypt the message, which can then only be decrypted using the private key. The system requires all participating parties to exchange keys, but email service providers such as Hushmail and Proton Mail have developed automated systems that transparently facilitate the key exchange processes for users exchanging messages within their network (Schaad et al., 2019).
The opposite process for encrypting a message can be used for signing a message. As previously noted, the sender will use the recipient’s public key to encrypt a message, which ensures only the recipient can read the message. In addition, the sender will sign the message with their own private key, which can only be read by their public key. This way the recipient knows the message did indeed come from the sender. Thus, authentication and non-repudiation is facilitated by digital signature, while message integrity and data confidentiality is facilitated by encryption (Schaad et al., 2019).
The security certificates used by S/MIME are managed by the X.509 specification. An implementation of the X.509 specification, for example, by an email service provider, is referred to as a Public Key Infrastructure (PKI). The X.509 specification for the management of certificates and certificate revocation lists recognizes “the limitations of the platforms users employ and in the sophistication and attentiveness of users” (Boeyen et al., 2008, pp. 7–8). The specification continues with the inherent limitations:
This manifests itself in minimal user configuration responsibility (e.g., trusted CA keys, rules), explicit platform usage constraints within the certificate, certification path constraints that shield the user from many malicious actions, and applications that sensibly automate validation functions. (Boeyen et al., 2008, p. 8)
Commercially managed PKI is intended to relieve users of the technical knowledge and hardware requirements for utilizing S/MIME. At the same time, it recognizes that user groups and organizations desired to host their own X.509 compliant PKI. To support the needs of all users, the specification allows for commercially operated public PKI and independent, private PKI. All PKI, public or private, establish trust via a Certificate Authority (CA) that validates all certificates issued within their PKI. However, there are significant differences in how CAs are recognized (Boeyen et al., 2008, p. 11).
Certificate Authorities
The entire PKI system is built on trust. Imagine that you recently moved to a new town and are looking for a contractor to make some home improvements. You have a friend from college that has lived in town for years, so you ask them for a reference. They give you the name of a local plumber that they have hired in the past and performed good work, which is very helpful because you have some plumbing work that needs to be done under the house. You contact the plumber who provides you with a fair estimate for the work, so you hire them for the job. They indeed perform excellent work just as your friend had said. You would like to have a sprinkler system installed, so you ask the plumber if they can provide an estimate for the work. The plumber does not work on sprinkler systems, but offers a reference for a local lawncare company that has a good reputation and that they have worked with in the past. You hire the lawncare company and during a break in the work, your spouse makes friendly small talk with one of the contractors and gets a reference for a local hairdresser.
By leveraging relationships with people you know, you were able to build a chain of trust from yourself to a lawncare specialist even though you had no prior interaction with them. Your spouse linked in to your chain of trust to build their own, creating a web of trust between several parties. Your private web of trust serves as your infrastructure for communication about life in town.
Because anyone can generate a security certificate, you need to have a chain of trust so you know which ones you should accept as valid. At the top of every CA is a “root” certificate. This root certificate is used to sign all the certificates within their PKI. This allows one user to trust any other user certificate in the chain even if they have never crossed paths before because they both trust the same root certificate.
Public PKI
Root certificates for public PKI are trusted because they are established by reputable organizations. For example, Microsoft operates a root CA, as do Internet security companies Thawte, Sectigo, DigiCert, Symantec, and VeriSign among hundreds of others. These high-level root CAs sign “intermediate” certificates for other organizations. These organizations then use their intermediate certificate to sign personal certificates, thus establishing a broad chain of trust, and ultimately a web of trust.
There are also a number of conventions that have developed around root certificate trust. These conventions are not part of the X.509 specification, but are intended to lend credibility to the existing root CAs and provide a “path to trust” for organizations petitioning for root CA recognition. Accreditation bodies like WebTrust developed a set of criteria to recognize the competence and performance of a root CA. Common criteria include disclosure of business practices, accounting, and key lifecycle management processes; existence and alignment with a Certificate Policy and Certificate Practice Statement; open validation of key integrity; subordinate CA certificate requests are accurate, authenticated and approved; publicly available list of third-party audits (Chartered Professional Accountants Canada, n.d.).
Private PKI
A private-PKI sounds like a dichotomy, but the correlation is applicable because the implementation is the same despite the naming convention. Ultimately, anyone can generate a root certificate and declare themselves a CA. What separates a public CA from a private CA is recognition of CA status. For example, browser developers include a list of default, trusted CAs with the installer file as a convenience to users. This allows the browser to validate and trust certificates presented by Internet services. However, the certificate presented must be trusted by one of the installed root CAs in order to be validated. And broadly speaking, the browser developer gets to decide what root certificates are included by default.
You can use your private root certificate to “self-sign” subordinate certificates, but the private root certificate will need to be installed and marked as trusted in the certificate store in order for the subordinate certificates to be validated and trusted. This process will then need to be replicated on every computer that needs to securely connect to your service. This type of private distribution infrastructure is feasible and useful for small groups, but quickly fails to scale economically. It should also be noted that cybersecurity experts advise against the use of private “self-signed” certificates even when they are only intended for use on an internal network due to the significant risk of impersonation.
DMARC
DMARC is a set of email authentication standards that govern how messages are created, sent, and received on the Internet. It operates primarily at the message transfer agent level at the sending server and receiving server to validate permissions to use a particular resource. There are several benefits derived from properly implemented DMARC. Email fraud, particularly sophisticated phishing attacks, are prevented from reaching the user inbox. Brand reputation is protected as only legitimate email can use your domain identity, and spam claiming to come from your brand will be prevented from reaching your customers. Feedback from message transfer agents provides visibility into who is sending email on your behalf, how messages are handled, and detailed analysis of bounced messages (Kucherawy & Zwicky, 2015).
The current specification, RFC 7489, implements four types of email authentication protocols. SPF checks to see if the IP address of your sending server is an authorized sender for your domain. DKIM checks for alignment like SPF, but also automates message integrity verification. Message Transfer Agent – Strict Transport Security (MTA-STS) ensures encrypted connections for messages in transit by checking security certificates between connections. And Brand Indicators for Message Identification (BIMI) displays a brand logo in an email client for visual user validation. In addition, DMARC instructs receiving servers how to handle email that fails validation (Kucherawy & Zwicky, 2015).
SPF
SPF was designed for use in email marketing to ensure brand reputation. Domains that are used to send large volumes of email are susceptible to exploitation by spammers. If a domain has a reputation for being “spammy”, it may be added to distributed email block-lists, resulting in legitimate messages failing to deliver. SPF works by checking if the IP address of your sending server is an authorized sender for your domain. When a user sends an email from your domain (i.e. user@example.com), the receiving server will check the headers of the message to determine the IP address of the sending server, and then query the domain (example.com) to verify if the IP address is on the authorized list of senders. When the domain in the From: header matches the Return-Path: header and the SPF Record query domain, the SPF check is considered to be “aligned.” It is possible to fail SPF alignment and still pass the SPF check, but it may affect deliverability (Kitterman, 2014).
SPF is implemented by adding an TXT SPF Record to the DNS for the domain. Take the following example record value:
v=spf1 ip4:100.64.28.5 include:smtp.example.com -all
This record indicates the SPF version, the IP address of an authorized sending server, the domain name of an authorized sending server, and the enforcement rule for failed checks (-all indicates a hard fail for all messages). It does not specify receiving servers as SPF is only concerned with validating the sending server has permission to send on behalf of the domain in the sender’s email address (Kitterman, 2014).
DKIM
DKIM was designed to provide message integrity and non-repudiation. The technique leverages PKI to sign messages at the domain level. The sending message transfer agent computes a cryptographic hash for the message content using the DKIM private key. When the message arrives to the receiving server, it queries the DKIM Record from the sending domain’s DNS to retrieve the public key, and then uses the public key to validate the cryptographic hash. If the message was altered in route the DKIM check will fail. It is important to note that DKIM does not encrypt a message. DKIM is not designed to provide data privacy. It only applies a digital signature to outgoing messages (Kucherawy et al., 2011).
DKIM also provides a secondary alignment check that functions the same way as the SPF alignment check. The receiving server expects the domain in the From: header to match the Return-Path: header and the DKIM Record query domain. The DKIM check is considered to be “aligned” when all of the domain paths match. It is possible to fail DKIM alignment and still pass the DKIM check, but it may affect deliverability (Kucherawy et al., 2011).
Also like SPF, DKIM is implemented by adding a TXT DKIM Record to the DNS for the domain. Take the following example record value:
v=dkim1;p=yourrandompublickeyprovidedbythesendingserver
The example record indicates the DKIM version number and the 2048-bit (255 character) public key. The public key value is provided during DKIM setup on the sending message transfer agent. A complete DKIM record will consist of two public keys and two DNS entries which function as primary and alternate. Only one record is required, but publishing multiple records ensures high-volume servers will be able to sign all outgoing messages (Kucherawy et al., 2011).
BIMI
BIMI is a method for controlling brand presentation in email and a user-facing check for validating message authenticity. The intent is to help customers feel confident they are communicating with the legitimate organization and not an impersonator. Messages with passing BIMI may also receive preferential deliverability, helping to ensure important messages make it to the inbox and do not land in spam (Kucherawy & Zwicky, 2015).
Similar to the other authentication types, BIMI is implemented by adding a TXT BIMI Record to the DNS for the domain. Take the following example record value:
v=BIMI1;l=https://url.to/logo.svg;a=https://url.to/certificate.pem
The example record indicates the BIMI version, the location of the authorized logo image, and the location to the optional security certificate. It is important to note that while SPF and DKIM operate independently of DMARC, BIMI requires DMARC enforcement before it will be accepted by email service providers. In addition, implementing BIMI is not the same as including a company logo in a message. The email service provider gets to decide how they will display your logo to the recipient (Kucherawy & Zwicky, 2015).
MTA-STS
MTA-STS is designed to ensure messages are routed over trusted, secure connections as it traverses the Internet. Resiliency in the email system comes from its ability to send traffic across any available route. Three different messages between the same sender and recipient all sent within seconds of each other could all take a different path across the Internet. The MTA-STS protocol validates the identity of each hop in the path to determine if any server in the path is an imposter (Margolis et al., 2018).
Again, MTA-STS is implemented by adding a TXT record to the DNS for the domain. Take the following example record value:
v=STSv1; id=86496301S00T000;
The example record indicates the STS version and the ID number of the current STS deployment. The ID number is arbitrary and can be any 32 random ASCII characters. The presence of the DNS record indicates your relay supports MTA-STS. The ID number should be changed to signal other relay servers to re-fetch the policy set for your domain (Margolis et al., 2018).
MTA-STS is generally only configured at the email service provider level as it requires constant monitoring and maintenance. However, it is an important behind-the-scenes element to email authentication and should be included as a consideration when selecting a service provider. The protocol significantly reduces the possibility of man-in-the-middle attacks and provides some of the privacy benefits of encryption even for plain text messages.
Conclusion
Some email providers have resorted to challenge-response systems that require positive affirmation before delivering a message. It is a simple and effective method that holds a message upon receipt and sends a reply to the sender to both validate the address and challenge the sender to verify they are human and not a bot. The sender then must reply back to the challenge before their original message will be delivered. While this type of system relieves the recipient from email sent by bots and from invalid addresses, it places responsibility for the delivery of a message on the sender. This is challenging to businesses to support at scale without some kind of automation, which then defeats the purpose of a challenge-response system in the first place.
The future of email deliverability is likely to rely on the Authenticated Received Chain (ARC) Protocol defined in experimental RFC 8617 by Anderson, Long, Blank, and Kucherawy (2019). ARC takes the DMARC process and extends it to every server in a message path. DMARC results of each hop are collected into ARC Sets that represent a complete assessment of a message from origin to destination. The intent is to be able to build an evidentiary-class chain of custody for every email message sent (Andersen et al., 2019). However, existing methods of email authentication are highly effective when properly implemented, and there are some simple server policy recommendations that can enhance their effectiveness.
All email should be required to pass three automated checks in order to be considered authentic. First, the message must conform with DMARC by aligning with both SPF and DKIM. Second, the message must pass ARC validation. Third, the message should be signed with a digital signature. Only by passing all three checks would a message be allowed to be delivered to the inbox. Messages that fail to pass all three checks but pass at least one should be directed to alternate delivery as specified by recipient preferences and settings at the individual level for personal email accounts and organizational level for business accounts. Messages that outright fail to pass all three checks should be blocked or delivered to a special quarantine folder for review.
Business communications, including internal messages and business-to-business communications, should be required to be encrypted as a fourth authentication check. The more restrictive requirements for business communications should also coincide with more restrictive failed delivery rules. The recommended action for unencrypted messages that pass all other requirements is to be returned as undelivered with a clear notification indicating the reason for non-delivery. All other authentication failures should be blocked. This approach also has the benefit of eliminating lost employee time wading through a spam folder to check for false positives. Messages to customers should always be signed to be considered valid, should be encrypted whenever possible, and should offer customers without a signing certificate to obtain one free of charge.
Email is people-centric. Email attacks target people, not infrastructure. The pervasive threat of email impersonation attacks and their increasing sophistication and prevalence have disrupted legitimate commerce from reliably reaching a user’s inbox. The rising volume of phishing attacks raises concerns, prompting global businesses to seek solutions from cybersecurity experts. The financial implications of missed client messages underscore the urgency for organizations to enhance email security to safeguard brand identity and client communication.
References
Andersen, K., Long, B., Blank, S., & Kucherawy, M. (2019). The Authenticated Received Chain (ARC) Protocol (Request for Comments RFC 8617). Internet Engineering Task Force. https://doi.org/10.17487/RFC8617
Anubhav, A. (2017, September 7). Fake Adobe website delivers BetaBot. Medium. https://blog.newskysecurity.com/fake-adobe-website-delivers-betabot-4114d1775a18
Baran, A. (2013). Stopping spam with sending session verification. Turkish Journal of Electrical Engineering & Computer Sciences, 21(2), 2259–2268. https://doi.org/10.3906/elk-1112-55
Beaman, C., & Isah, H. (2022). Anomaly Detection in Emails using Machine Learning and Header Information. arXiv.Org. ProQuest Central; SciTech Premium Collection. http://ezproxy.apus.edu/login?qurl=https%3A%2F%2Fwww.proquest.com%2Fworking-papers%2Fanomaly-detection-emails-using-machine-learning%2Fdocview%2F2641678227%2Fse-2%3Faccountid%3D8289
Belding, G. (2020, December 18). Phishing: Reputational damages. Infosec Institute. https://resources.infosecinstitute.com/topics/phishing/reputational-damages/
Boeyen, S., Santesson, S., Polk, T., Housley, R., Farrell, S., & Cooper, D. (2008). Internet X.509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL) Profile (Request for Comments RFC 5280). Internet Engineering Task Force. https://doi.org/10.17487/RFC5280
Chartered Professional Accountants Canada. (n.d.). WebTrust Seal program principles and criteria and practitioner guidance. Retrieved January 1, 2024, from https://www.cpacanada.ca/en/business-and-accounting-resources/audit-and-assurance/overview-of-webtrust-services/principles-and-criteria
Cluley, G. (2015, June 29). Researcher highlights the homographic phishing problem. Graham Cluley. https://grahamcluley.com/lloydsbank-homographic-phishing-problem/
Craig, A. (2022, March 16). What is Email Impersonation? Everything You Need to Know. Tessian. https://www.tessian.com/blog/inside-domain-name-email-impersonation/
Davis, C., Simpson, D., Rathinam, M., Piesco, J., Chakrabarti, R., & Athavale, M. (2023, September 8). Anti-spam message headers. https://learn.microsoft.com/en-us/microsoft-365/security/office-365-security/message-headers-eop-mdo?view=o365-worldwide
Email Impersonation Attacks Reach All-Time High According to Latest Report from Fortra. (2023). Database & Network Journal, 53(3), 24–26.
Freed, N., & Borenstein, N. S. (1996). Multipurpose Internet Mail Extensions (MIME) Part Five: Conformance Criteria and Examples (Request for Comments RFC 2049). Internet Engineering Task Force. https://doi.org/10.17487/RFC2049
Gungor, A. (2019, March 29). Using The Content-Length Header Field In Email Forensics. Forensic Focus [BLOG]. ProQuest Central; SciTech Premium Collection. http://ezproxy.apus.edu/login?qurl=https%3A%2F%2Fwww.proquest.com%2Fblogs-podcasts-websites%2Fusing-content-length-header-field-email-forensics%2Fdocview%2F2253704051%2Fse-2%3Faccountid%3D8289
Hoffman, P. E., & Blanchet, M. (2003). Preparation of Internationalized Strings (“stringprep”) (Request for Comments RFC 3454). Internet Engineering Task Force. https://doi.org/10.17487/RFC3454
ICANN Bringing the Languages of the World to the Global Internet; Fast Track Process for Internationalized Domain Names Launches Nov 16. (2016, November). https://www.icann.org/en/announcements/details/icann-bringing-the-languages-of-the-world-to-the-global-internet–fast-track-process-for-internationalized-domain-names-launches-nov-16-30-10-2009-en
Isaac, M. (2018, October 12). Facebook Hack Included Search History and Location Data of Millions. The New York Times. https://www.nytimes.com/2018/10/12/technology/facebook-hack-investigation.html
Kaur, K., Gupta, I., & Singh, A. K. (2018). Data Leakage Prevention: E-Mail Protection via Gateway. Journal of Physics: Conference Series, 933(1). ProQuest Central; SciTech Premium Collection. https://doi.org/10.1088/1742-6596/933/1/012013
Kawasaki, G. (2011). Enchantment: The Art of Changing Hearts, Minds, and Actions. Penguin Publishing Group.
Kitterman, S. (2014). Sender Policy Framework (SPF) for Authorizing Use of Domains in Email, Version 1 (Request for Comments RFC 7208). Internet Engineering Task Force. https://doi.org/10.17487/RFC7208
Korb, J. T. (1983). Standard for the transmission of IP datagrams over public data networks (Request for Comments RFC 877). Internet Engineering Task Force. https://doi.org/10.17487/RFC0877
Kucherawy, M., Crocker, D., & Hansen, T. (2011). DomainKeys Identified Mail (DKIM) Signatures (Request for Comments RFC 6376). Internet Engineering Task Force. https://doi.org/10.17487/RFC6376
Kucherawy, M., & Zwicky, E. (2015). Domain-based Message Authentication, Reporting, and Conformance (DMARC) (Request for Comments RFC 7489). Internet Engineering Task Force. https://doi.org/10.17487/RFC7489
Limor, Y. (2021, August 13). The hackers: A closer look at the shadowy world of offensive cyber. Www.Israelhayom.Com. https://www.israelhayom.com/2021/08/13/the-hackers-a-closer-look-at-the-shadowy-world-of-offensive-cyber/
Margolis, D., Risher, M., Ramakrishnan, B., Brotman, A., & Jones, J. (2018). SMTP MTA Strict Transport Security (MTA-STS) (Request for Comments RFC 8461). Internet Engineering Task Force. https://doi.org/10.17487/RFC8461
Palme, J. (1997). Common Internet Message Headers (Request for Comments RFC 2076). Internet Engineering Task Force. https://doi.org/10.17487/RFC2076
Partridge, C. (2008). The Technical Development of Internet Email. IEEE Annals of the History of Computing, 30(2), 3–29. https://doi.org/10.1109/MAHC.2008.32
Resnick, P. (2008). Internet Message Format (Request for Comments RFC 5322). Internet Engineering Task Force. https://doi.org/10.17487/RFC5322
Schaad, J., Ramsdell, B. C., & Turner, S. (2019). Secure/Multipurpose Internet Mail Extensions (S/MIME) Version 4.0 Message Specification (Request for Comments RFC 8551). Internet Engineering Task Force. https://doi.org/10.17487/RFC8551
Shewale, R. (2023, October 11). How Many Emails Are Sent Per Day (2023-2027). https://www.demandsage.com/how-many-emails-are-sent-per-day/
Silnov, D. S. (2016). An Analysis of Modern Approaches to the Delivery of Unwanted Emails (Spam). Indian Journal of Science and Technology, 9(4), 1–4. https://doi.org/10.17485/ijst/2016/v9i4/84803
Sirbu, M. (1988). Content-type header field for Internet messages (Request for Comments RFC 1049). Internet Engineering Task Force. https://doi.org/10.17487/RFC1049
Umawing, J. (2017, October 5). Out of character: Homograph attacks explained, Malwarebytes Labs. Malwarebytes. https://www.malwarebytes.com/blog/news/2017/10/out-of-character-homograph-attacks-explained/